Parallel programming is not a new concept; it has
been around for some time, although mostly on large or distributed
systems. Parallel computing has more recently been available on personal
computers with Threading Building Blocks (TBB), OpenMP, and other
parallel solutions. So although parallel computing might seem new, the
concepts are actually mature. For example, design patterns have been
developed to help programmers design, architect, and implement a robust,
correct, and scalable parallel application. The book Patterns for Parallel Programming
by Timothy G. Mattson, Beverly A. Sanders, and Berna L. Massingill
(Addison-Wesley Professional, 2004) provides a comprehensive study on
parallel patterns, along with a detailed explanation of the available
design patterns and best practices for parallel programming. Another
book, Parallel Programming with Microsoft .NET: Design Patterns for Decomposition and Coordination on Multicore Architectures
by Colin Campbell et al. (Microsoft Press, 2010) is an important
resource for patterns and best practices that target the .NET Framework
and TPL.
Developers on average do not
write much unique code. Most code concepts have been written somewhere
before. Software pattern engineers research this universal code base to
isolate standard patterns and solutions for common problems in a domain
space. You can use these patterns as the building blocks that form the
foundation of a stable application. Around these core components, you
add the unique code for your application, as illustrated in the
following diagram. This approach not only results in a stable
application but is also a highly efficient way to develop an
application.
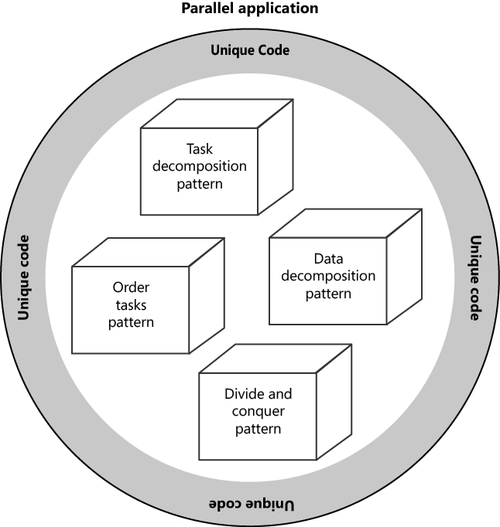
Design
patterns should be an integral part of the software development life
cycle of every application. These patterns require thorough knowledge of
your problem domain. All object-oriented programs model a problem
domain, and parallel applications are no exception. As applications
become more complex, knowing the problem domain increases in importance.
Patterns for Parallel Programming defines four phases of parallel development:
The first two phases are
design and analysis, which include tasks such as finding exploitable
concurrency. These phases are the precursors to actually writing code.
Later, you map the analysis onto code by using the Support Structures
and Implementation Mechanisms phases.You can consider the TPL as a generic implementation of this pattern; it maps parallel programming onto the .NET Framework.
I urge you to explore parallel design patterns so you can benefit from the hard work of other parallel applications developers.
1. The Finding Concurrency Pattern
The first phase is the most
important. In this phase, you identify exploitable concurrency. The
challenge involves more than identifying opportunities for concurrency,
because not every potential concurrency is worth pursuing. The goal is
to isolate opportunities of concurrency that are worth exploiting.
The Finding Concurrency
pattern begins with a review of the problem domain. Your goal is to
isolate tasks that are good candidates for parallel programming—or
conversely, exclude those that are not good candidates. You must weigh
the benefit of exposing specific operations as parallel tasks versus the
cost. For example, the performance gain for parallelizing a for loop with a short operation might not offset the scheduling overhead and the cost of running the task.
When searching for
potential parallel tasks, review extended blocks of compute-bound code
first. This is where you will typically find the most intense
processing, and therefore also the greatest potential benefit from
parallel execution.
Next, you decompose exploitable concurrency into parallel tasks. You can decompose operations on either the code or data axis (Task Decomposition and Data Decomposition,
respectively). The typical approach is to decompose operations into
several units. It’s easier to load balance a large number of discrete
tasks than a handful of longer tasks. In addition, tasks of relatively
equal length are easier to load balance than tasks of widely disparate
length.
1.1. The Task Decomposition Pattern
In the Task
Decomposition pattern, you decompose code into separate parallel tasks
that run independently, with minimal or no dependencies. For example,
functions are often excellent candidates for refactoring as parallel
tasks. In object-oriented programming, functions should do one thing.
However, this is not always the case. For longer functions, evaluate
whether the function performs more than one task. If so, you might be
able to decompose the function into multiple discrete tasks, improving
the opportunities for parallelism.
1.2. The Data Decomposition Pattern
In the Data
Decomposition pattern, you decompose data collections, such as lists,
stacks, and queues, into partitions for parallel processing. Loops that
iterate over data collections are the best locations for decomposing
tasks by using the Data Decomposition pattern. Each task is identical
but is assigned to a different portion of the data collection. If the
tasks have short durations, you should consider grouping multiple tasks
together so that they execute as a chunk on a thread, to improve overall
efficiency.
1.3. The Group Tasks Pattern
After completing the Task and
Data Decomposition patterns, you will have a basket of tasks. The next
two patterns identify relationships between these tasks. The Group Task
pattern groups related tasks, whereas the Order Tasks pattern imposes an
order to the execution of tasks.
You should consider grouping tasks in the following circumstances:
Group tasks
together that must start at the same time. The Order Task pattern can
then refer to this group to set that constraint.
Group tasks that contribute to the same calculation (reduction).
Group tasks that share the same operation, such as loop operation.
Group tasks that share a common resource, where simultaneous access is not thread safe.
The most important reason to create task groups is to place constraints on the entire group rather than on individual tasks.
1.4. The Order Tasks Pattern
The Order Tasks pattern is
the second pattern that sets dependencies based on task relationships.
This pattern identifies dependencies that place constraints on the order
(the sequence) of task execution. In this pattern, you often reference
groups of tasks defined in the Group Task pattern. For example, you
might reference a group of tasks that must start together.
Do not overuse this pattern. Ordering implies synchronization at best, and sequential execution at worst.
Some example of order dependencies are:
Start dependency This is when tasks must start at the same time. Here the constraint is the start time.
Predecessor dependency This occurs when one task must start prior to another task.
Successor dependency This happens when a task is a continuation of another task.
Data dependency This is when a task cannot start until certain information is available.
1.5. The Data Sharing Pattern
Parallel
tasks may access shared data, which can be a dependency between tasks.
Proper management is essential for correctness and to avoid problems
such as race conditions and data corruptions. The Data Sharing pattern
describes various methods for managing shared data. The goals are to
ensure that tasks adhering to this pattern are thread safe and that the
application remains scalable.
When possible, tasks should
consume thread-local data. Thread-local data is private to the task and
not accessible from other tasks. Because of this isolation, thread-local
data is exempt from most data-sharing constraints. However, tasks that
use thread-local data might require shared data for consolidation,
accumulation, or other types of reduction. Reduction is the
consolidation of partial results from separate parallel operations into a
single value. When the reduction is performed, access to the shared
data must be coordinated through some mechanism, such as thread
synchronization.
Sharing data is expensive. Proposed solutions to safely access shared data typically involve some sort of synchronization. The best solution for sharing data is not to share data.
This includes copying the shared data to a thread-local variable. You
can then access the data privately during a parallel operation. After
the operation is complete, you can perform a replacement or some type of
merge with the original shared data to minimize synchronization.
The type of data access can affect the level of synchronization. Common data access types are summarized here:
Read-only This is preferred and frequently requires no synchronization.
Write-only
You must have a policy to handle contention on the write.
Alternatively, you can protect the data with exclusive locks. However,
this can be expensive. An example of write-only is initializing a data
collection from independent values.
Read-write The key word here is the write.
Copy the data to a thread-local variable. Perform the update operation.
Write results to the shared data, which might require some level of
synchronization. If more reads are expected than writes, you might want
to implement a more optimistic data sharing model—for example, spinning
instead of locking.
Reduction
The shared data is an accumulator. Copy the shared data to a
thread-local variable. You can then perform an operation to generate a
partial result. A reduction task is responsible for applying partial
results to some sort of accumulator. Synchronization is limited to the
reduction method, which is more efficient. This approach can be used to
calculate summations, averages, counts, maximum value, minimal value,
and more.
2. The Algorithm Structure Pattern
The
result of the Finding Concurrency phase is a list of tasks,
dependencies, and constraints for a parallel application. The phase also
involves grouping related tasks and setting criteria for ordering
tasks. In the Algorithm Structure phase, you select the algorithms you
will use to execute the tasks. These are the algorithms that you will
eventually implement for the program domain.
The algorithms included in the Algorithm Structure pattern adhere to four principles. These algorithms must:
Make effective use of processors.
Be transparent and maintainable by others.
Be agnostic to hardware, operating system, and environment.
Be efficient and scalable.
As mentioned, algorithms
are implementation-agnostic. You might have constructs and features in
your environment that help with parallel development and performance.
The Implementation Mechanisms phase describes how to implement parallel
patterns in your specific environment.
The Algorithm Structure pattern introduces several patterns based on algorithms:
Task Parallelism Pattern
Arrange tasks to run efficiently as independent parallel operations.
Actually, having slightly more tasks than processor cores is
preferable—especially for input/output bound tasks. Input/output bound
tasks might become blocked during input/output operations. When this
occurs, extra tasks might be needed to keep additional processor cores
busy.
Divide and Conquer Pattern
Decompose a serial operation into parallel subtasks, each of which
returns a partial solution. These partial solutions are then
reintegrated to calculate a complete solution. Synchronization is
required during the reintegration but not during the entire operation.
Geometric Decomposition Pattern
Reduce a data collection into chunks that are assigned the same
parallel operation. Larger chunks can be harder to load balance, whereas
smaller chunks are better for load balancing but are less efficient
relative to parallelization overhead.
Recursive Data Pattern Perform parallel operations on recursive data structures, such as trees and link lists.
Pipeline Pattern Apply
a sequence of parallel operations to a shared collection or independent
data. The operations are ordered to form a pipeline of tasks that are
applied to a data source. Each task in the pipeline represents a phase.
You should have enough phases to keep each processor busy. At the start
and end of pipeline operations, the pipeline might not be full.
Otherwise, the pipeline is full with tasks and maximizes processor
utilization.
3. The Supporting Structures Pattern
The Supporting
Structures pattern describes several ways to organize the implementation
of parallel code. Fortunately, several of these patterns are already
implemented in the TPL as part of the .NET Framework. For example, the
.NET Framework 4 thread pool is one implementation of the Master/Worker
pattern.
There are four Supporting Structures patterns:
SPMD (Single Program/Multiple Data)
A single parallel operation is applied to multiple data sequences. In a
parallel program, the processor cores often execute the same task on a
collection of data.
Master/Worker The process (master) sets up a pool of executable units (workers),
such as threads, that execute concurrently. There is also a collection
of tasks whose execution is pending. Tasks are scheduled to run in
parallel on available workers. In this manner, the workload can be
balanced across multiple processors. The .NET Framework 4 thread pool
provides an implementation of this pattern.
Loop Parallelism
Iterations of a sequential loop are converted into separate parallel
operations. Resolving dependencies between loop iterations is one of the
challenges. Such dependencies were perhaps inconsequential in
sequential applications but are problematic in a parallel version. The
.Net Framework 4 provides various solutions for loop parallelism,
including Parallel.For, Parallel.ForEach, and PLINQ (Parallel Language Integration Query).
Fork/Join
Work is decomposed into separate tasks that complete some portion of
the work. A unit of execution, such as a thread, spawns the separate
tasks and then waits for them to complete. This is the pattern for the Parallel.Invoke method in the TPL.
The Supporting Structure
phase also involves patterns for sharing data between multiple parallel
tasks: the Shared Data, Shared Queue, and Distributed Array patterns.
These are also already implemented in the .NET Framework, available as
collections in the System.Collections.Concurrent namespace.